Ah source control, if there’s a more essential tool which indiscriminately spans programming languages without favour, I’m yet to see it. It’s an essential component of how so many of us work; the lifeblood of many development teams, if you like. So why do we often get it so wrong? Why are some of the really core, fundamentals of version control systems often so poorly understood?
I boil it down to 10 practices – or “commandments” if you like – which often break down or are not properly understand to begin with. These are all relevant to version control products of all types and programming languages of all flavours. I’ll pick some examples from Subversion and .NET but they’re broadly applicable to other technologies.
1. Stop right now if you’re using VSS – just stop it!
It’s dead. Let it go. No really, it’s been on life support for years, taking its dying gasps as younger and fitter VCS tools have rocketed past it. And now it’s really seriously about to die as Microsoft finally pulls the plug next year (after several stays of execution).
In all fairness, VSS was a great tool. In 1995. It just simply got eclipsed by tools like Subversion then the distributed guys like Git and Mercurial. Microsoft has clearly signalled its intent to supersede it for many years now – the whole TFS thing wasn’t exactly an accident!
The point is that VSS is very broadly, extensively, almost unanimously despised due to a series of major shortcomings by today’s standards. Colloquially known as Microsoft’s source destruction system, somehow it manages to just keep clinging on to life despite extensively documented glitches, shortcomings and essential functionality (by today’s standards), which simply just doesn’t exist.


2. If it’s not in source control, it doesn’t exist
Repeat this mantra daily – “The only measure of progress is working code in source control”. Until your work makes an appearance in the one true source of code truth – the source control repository for the project – it simply doesn’t exist.
Sure, you’ve got it secreted away somewhere on your local machine but that’s not really doing anyone else any good now, is it? They can’t take your version, they can’t merge theirs, you can’t deploy it (unless you’re deploying it wrong) and you’re one SSD failure away from losing it all permanently.
Once you take the mindset of it not existing until it’s committed, a whole bunch of other good practices start to fall into place. You break tasks into smaller units so you can commit atomically. You integrate more frequently. You insure yourself against those pesky local hardware failures.
But more importantly (at least for your team lead), you show that you’re actually producing something. Declining burn down charts or ticked off tasks lists are great, but what do they actually reconcile with? Unless they correlate with working code in source control, they mean zip.
3. Commit early, commit often and don’t spare the horses
Further to the previous point, the only way to avoid “ghost code” – that which only you can see on your local machine – is to get it into VCS early and often and don’t spare the horses. Addressing the issues from the previous point is one thing the early and often approach achieves, but here’ a few others which can make a significant difference to the way you work:
- Every committed revision gives you a rollback position. If you screw up fundamentally (don’t lie, we all do!), are you rolling back one hour of changes or one week?
- The risk of a merge nightmare increases dramatically with time. Merging is never fun. Ever. When you’ve not committed code for days and you suddenly realise you’ve got 50 conflicts with other people’s changes, you’re not going to be a happy camper.
- It forces you to isolate features into discrete units of work. Let’s say you’ve got a 3 man day feature to build. Oftentimes people won’t commit until the end of that period because they’re trying to build the whole box and dice into one logical unit. Of course a task as large as this is inevitably comprised of smaller, discrete functions and committing frequently forces you to identify each of these, build them one by one and commit them to VCS.
When you work this way, your commit history inevitably starts to resemble a semi-regular pattern of multiple commits each work day. Of course it’s not always going to be a consistent pattern, there are times we stop and refactor or go through testing phases or any other manner of perfectly legitimate activities which interrupt the normal development cycle.
However, when I see an individual – and particularly an entire project – where I know we should be in a normal development cycle and there are entire days or even multiple days where nothing is happening, I get very worried. I’m worried because as per the previous point, no measurable work has been done but I’m also worried because it usually means something is wrong. Often development is happening in a very “boil the ocean” sort of way (i.e. trying to do everything at once) or absolutely nothing of value is happening at all because people are stuck on a problem. Either way, something is wrong and source control is waving a big red flag to let you know.
4. Always inspect your changes before committing
Committing code into source control is easy – too easy! (Makes you wonder why the previous point seems to be so hard.) Anyway, what you end up with is changes and files being committed with reckless abandon. “There’s a change somewhere beneath my project root – quick – get it committed!”
What happens is one (or both) of two things: Firstly, people inadvertently end up with a whole bunch of junk files in the repository. Someone sees a window like the one below, clicks “Select all” and bingo – the repository gets polluted with things like debug folders and other junk that shouldn’t be in there.
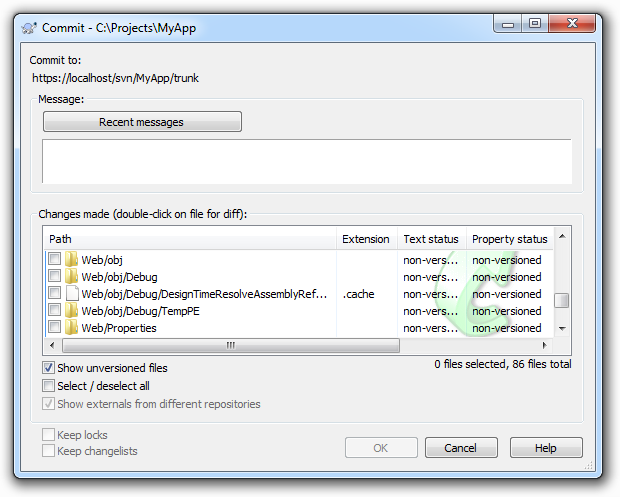
Or secondly, people commit files without checking what they’ve actually changed. This is real easy to do once you get things like configuration or project definition files where there are a lot going on at once. It makes it really easy to inadvertently put things into the repository that simply weren’t intended to be committed and then of course they’re quite possibly taken down by other developers. Can you really remember everything you changed in that config file?
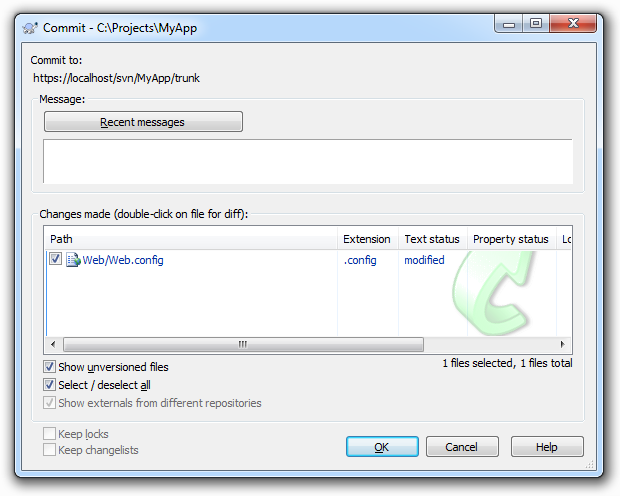
The solution is simple: you must inspect each change immediately before committing. This is easier than it sounds, honest. The whole “inadvertently committed file” thing can be largely mitigated by using the “ignore” feature many systems implement. You never want to commit the Thumbs.db file so just ignore it and be done with it. You also may not want to commit every file that has changed in each revision – so don’t!
As for changes within files, you’ve usually got a pretty nifty diff function in there somewhere. Why am I committing that Web.config file again?
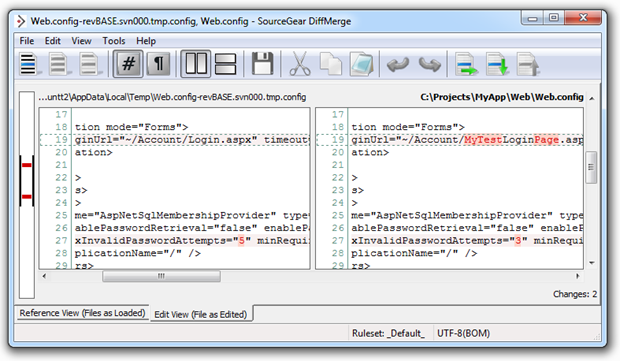
Ah, I remember now, I wanted to decrease the maximum invalid password attempts from 5 down to 3. Oh, and I played around with a dummy login page which I definitely don’t want to put into the repository. This practice of pre-commit inspection also makes it much easier when you come to the next section…
5. Remember the axe-murderer when writing commit messages
There’s an old adage (source unknown), along the lines of “Write every commit message like the next person who reads it is an axe-wielding maniac who knows where you live”. If I was that maniac and I’m delving through reams of your code trying to track down a bug and all I can understand from your commit message is “updated some codes”, look out, I’m coming after you!
The whole idea of commit messages is to explain why you committed the code. Every time you make any change to code, you’re doing it for a reason. Maybe something was broken. Maybe the customer didn’t like the colour scheme. Maybe you’re just tweaking the build configuration. Whatever it is, there’s a reason for it and you need to leave this behind you.
Why? Well there are a few different reasons and they differ depending on the context. For example, using a “blame” feature or other similar functionality which exposes who changed what and hopefully, why. I can’t remember what I was doing in the Web.config of this project 18 months ago or why I was mucking around with app settings, but because I left a decent commit message, it all becomes very simple:
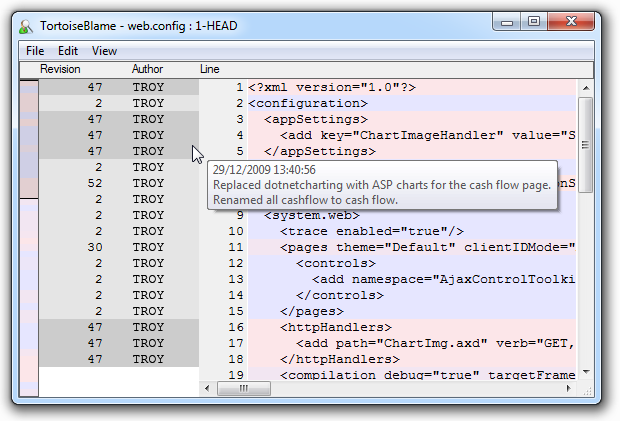
It’s a similar thing for looking at changes over time. Whether I want to see the entire history of a file, like below, or I just want to see what the team accomplished yesterday, having a descriptive paper trail of comments means it doesn’t take much more than a casual glance to get an idea of what’s going on.
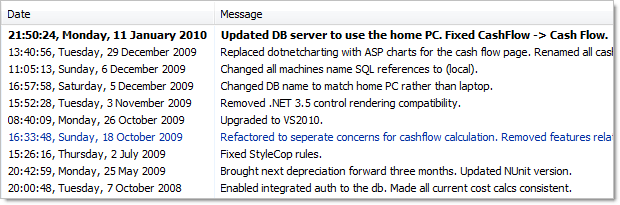
And finally, commit messages are absolutely invaluable when it comes to tracking down errors. For example, getting to the bottom of why the build is breaking in your continuous integration environment. Obviously my example is overtly obvious, but the point is that bringing this information to the surface can turn tricky problems into absolute no-brainers.
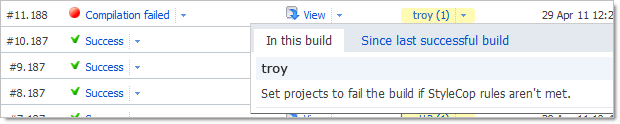
With this in mind, here are some anti-patterns of good commit messages:
- Some shit.
- It works!
- fix some fucking errors
- fix
- Fixed a little bug…
- Updated
- typo
- Revision 1024!!
Ok, I picked these all out of the Stack Overflow question about What is the WORST commit message you have ever authored but the thing is that none of them are that dissimilar to many of the messages I’ve seen in the past. They tell you absolutely nothing about what has actually happened in the code; they’re junk messages.
One last thing about commit messages; subsequent commit messages from the same author should never be identical. The reason is simple: you’re only committing to source control because something has changed since the previous version. Your code is now in a different state to that previous version and if your commit message is accurate and complete, it logically cannot be identical. Besides, if it was identical (perhaps there’s a legitimate edge-case there somewhere), the log is now a bit of a mess to read as there’s no way to discern the difference between the two commits.
6. You must commit your own changes – you can’t delegate it
As weird as this sounds, it happens and I’ve seen it more than once, most recently just last week. What’s happening here is that the source control repository is being placed on a pedestal. For various reasons, the team is viewing it as this sanitised, pristine environment of perfect code. In order to maintain this holy state, code is only committed by a lead developer who carefully aggregates, reviews and (assumedly) tweaks and improves the code before it’s committed.
It’s pretty easy to observe this pattern from a distance. Very infrequent commits (perhaps weekly), only a single author out of a team with multiple developers and inevitably, conflict chaos if anyone else has gone near the project during that lengthy no-commit period. Very, very nasty stuff.
There are two major things wrong here: Firstly, source control in not meant to be this virginal, unmolested stash of pristine code; at least not throughout development cycles. It’s meant to be a place where the team integrates frequently, rolls back when things go wrong and generally comes together around a single common base. It doesn’t have to be perfect throughout this process, it only has to (try to) achieve that state at release points in the application lifecycle.
The other problem – and this is the one that really blow me away – is that from the developer’s perspective, this model means you have no source control! It means no integration with code from peers, no rollback, no blame log, no nothing! You’re just sitting there in your little silo writing code and waiting to hand it off to the boss at some arbitrary point in the future.
Don’t do this. Ever.
7. Versioning your database isn’t optional
This is one of those ones that everyone knows they should be doing but very often they just file it away in the “too hard” basket. The problem you’ve got is that many (most?) applications simply won’t run without their database. If you’re not versioning the database, what you end up with is an incomplete picture of the application which in practice is rendered entirely useless.
Most VCS systems work by simply versioning files on the file system. That’s just fine for your typical app files like HTML page, images, CSS, project configuration files and anything else that sits on the file system in nice discrete little units. Problem is that’s not quite the way relational databases work. Instead, you end up with these big old data and log files which encompass a whole bunch of different objects and data. This is pretty messy stuff when it comes to version control.
 What changes the proposition of database versioning these days is the accessibility of tools like the very excellent SQL Source Control from Red Gate. I wrote about this in detail last year in the post about Rocking your SQL Source Control world with Red Gateso I won’t delve into the detail again; suffice to say that database versioning is now easy!
What changes the proposition of database versioning these days is the accessibility of tools like the very excellent SQL Source Control from Red Gate. I wrote about this in detail last year in the post about Rocking your SQL Source Control world with Red Gateso I won’t delve into the detail again; suffice to say that database versioning is now easy!
Honestly, if you’re not versioning your databases by now you’re carrying a lot of risk in your development for no good reason. You have no single source of truth, no rollback position and no easy collaboration with the team when you make changes. Life is just better with the database in source control 🙂
8. Compilation output does not belong in source control
Here’s an easy way of thinking about it: nothing that is automatically generated as a result of building your project should be in source control. For the .NET folks, this means pretty much everything in the “bin” and “obj” folders which will usually be .dll and .pdb files.
Why? Because if you do this, your co-workers will hate you. It means that every time they pull down a change from VCS they’re overwriting their own compiled output with yours. This is both a merge nightmare (you simply can’t do it), plus it may break things until they next recompile. And then once they do recompile and recommit, the whole damn problem just gets repeated in the opposite direction and this time you’re on the receiving end. Kind of serves you right, but this is not where we want to be.
Of course the other problem is that it’s just wasteful. It’s wasted on the source control machine disk, it’s wasted in bandwidth and additional latency every time you need to send it across the network and it’s sure as hell a waste of your time every time you’ve got to deal with the inevitable conflicts that this practice produces.
So we’re back to the “ignore” patterns mentioned earlier on. Once paths such as “bin” and “obj” are set to ignore, everything gets really, really simple. Do it once, commit the rule and everybody is happy.
In fact I’ve even gone so far as to write pre-commit hooks that execute on the VCS server just so this sort of content never makes it into source control to begin with. Sure, it can be a little obtrusive getting your hand slapped by VCS but, well, it only happens when you deserve it! Besides, I’d far rather put the inconvenience back on the perpetrator rather than pass it on to the entire time by causing everyone to have conflicts when they next update.
9. Nobody else cares about your personal user settings
To be honest, I think that quite often people aren’t even aware they’re committing their own personal settings into source control. Here’s what the problem is: many tools will produce artefacts which manage your own personal, local configurations. They’re only intended to be for you and they’ll usually be different to everyone else’s. If you put them into VCS, suddenly you’re all overwriting each other’s personal settings. This is not good.
Here’s an example of a typical .NET app:
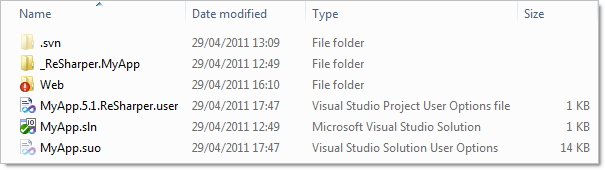
The giveaway should be the extensions and type descriptions but in case it’s not immediately clear, the .ReSharper.user file and the .suo (Solution User Options) file are both, well, yours. They’re nobody else’s.
Here’s why: Let’s take a look inside the ReSharper file:
<Configuration>
<SettingsComponent>
<string />
<integer />
<boolean>
<setting name="SolutionAnalysisEnabled">True</setting>
</boolean>
</SettingsComponent>
<RecentFiles>
<RecentFiles>
<File id="F985644D-6F99-43AB-93F5-C1569A66B0A7/f:Web.config"
caret="1121" fromTop="26" />
<File id="F985644D-6F99-43AB-93F5-C1569A66B0A7/f:Site.Master.cs"
caret="0" fromTop="0" />
In this example, the fact that I enabled solution analysis is recorded in the user file. That’s fine by me, I like it, other people don’t. Normally because they’ve got an aging, bargain basement PC, but I digress. The point is that this is my setting and I shouldn’t be forcing it upon everyone else. It’s just the same with the recent files node; just because I recently opened these files doesn’t mean it should go into someone else’s ReSharper history.
Amusing sidenote: the general incompetence of VSS means ignoring .ReSharper.user files is a bit of a problem.
It’s a similar story with the .suo file. Whilst there’s not much point looking inside it (no pretty XML here, it’s all binary), the file records things like the state of the solution explorer, publishing settings and other things that you don’t want to go forcing on other people.
So we’re back to simply ignoring these patterns again. At least if you’re not running VSS, that is.
10. Dependencies need a home too
 This might be the last of the Ten Commandments but it’s a really, really important one. When an app has external dependencies which are required for it to successfully build and run, get them into source control! The problem people tend to have is that they get everything behaving real nice in their own little environment with their own settings and their own local dependencies then they commit everything into source control, walk away and think things are cool. And they are, at least until someone else who doesn’t have some same local decencies available pulls it down and everything fails catastrophically.
This might be the last of the Ten Commandments but it’s a really, really important one. When an app has external dependencies which are required for it to successfully build and run, get them into source control! The problem people tend to have is that they get everything behaving real nice in their own little environment with their own settings and their own local dependencies then they commit everything into source control, walk away and think things are cool. And they are, at least until someone else who doesn’t have some same local decencies available pulls it down and everything fails catastrophically.
I was reminded of this myself today when I pulled an old project out of source control and tried to build it:
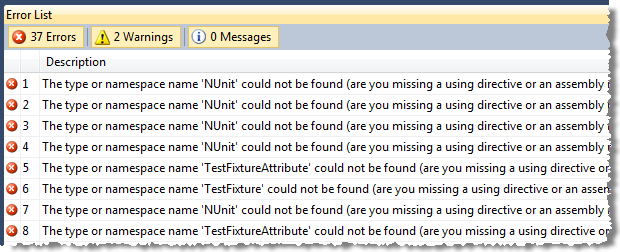
I’d worked on the assumption that NUnit would always be there on the machine but this time that wasn’t the case. Fortunately the very brilliant NuGet bailed me out quickly, but it’s not always that easy and it does always take some fiddling when you start discovering that dependencies are missing. In some cases, they’re not going to be publicly available and it can be downright painful trying to track them down.
I had this happen just recently where I pulled down a project from source control, went to run it and discovered there was a missing assembly located in a path that began with “c:\Program Files…”. I spent literally hours trying to track down the last guy who worked on this (who of course was on the other side of the world), get the assembly, put it in a “Libraries” folder in the project and actually get it into VCS so the next poor sod who comes across the project doesn’t go through the same pain.
Of course the other reason this is very important is that if you’re working in any sort of continuous integration environment, your build server isn’t going to have these libraries installed. Or at least you shouldn’t be dependent on it. Doug Rathbone made a good point about this recently when he wrote about Third party tools live in your source control. It’s not always possible (and we had some good banter to that effect), but it’s usually a pretty easy proposition.
So do everyone a favour and make sure that everything required for your app to actually build and run is in VCS from day 1.
Summary
None of these things are hard. Honestly, they’re really very basic: commit early and often, know what you’re committing and that it should actually be in VCS, explain your commits and make sure you do it yourself, don’t forget the databases and don’t forget the dependencies. But please do forget VSS 🙂
via: http://www.troyhunt.com/2011/05/10-commandments-of-good-source-control.html














